
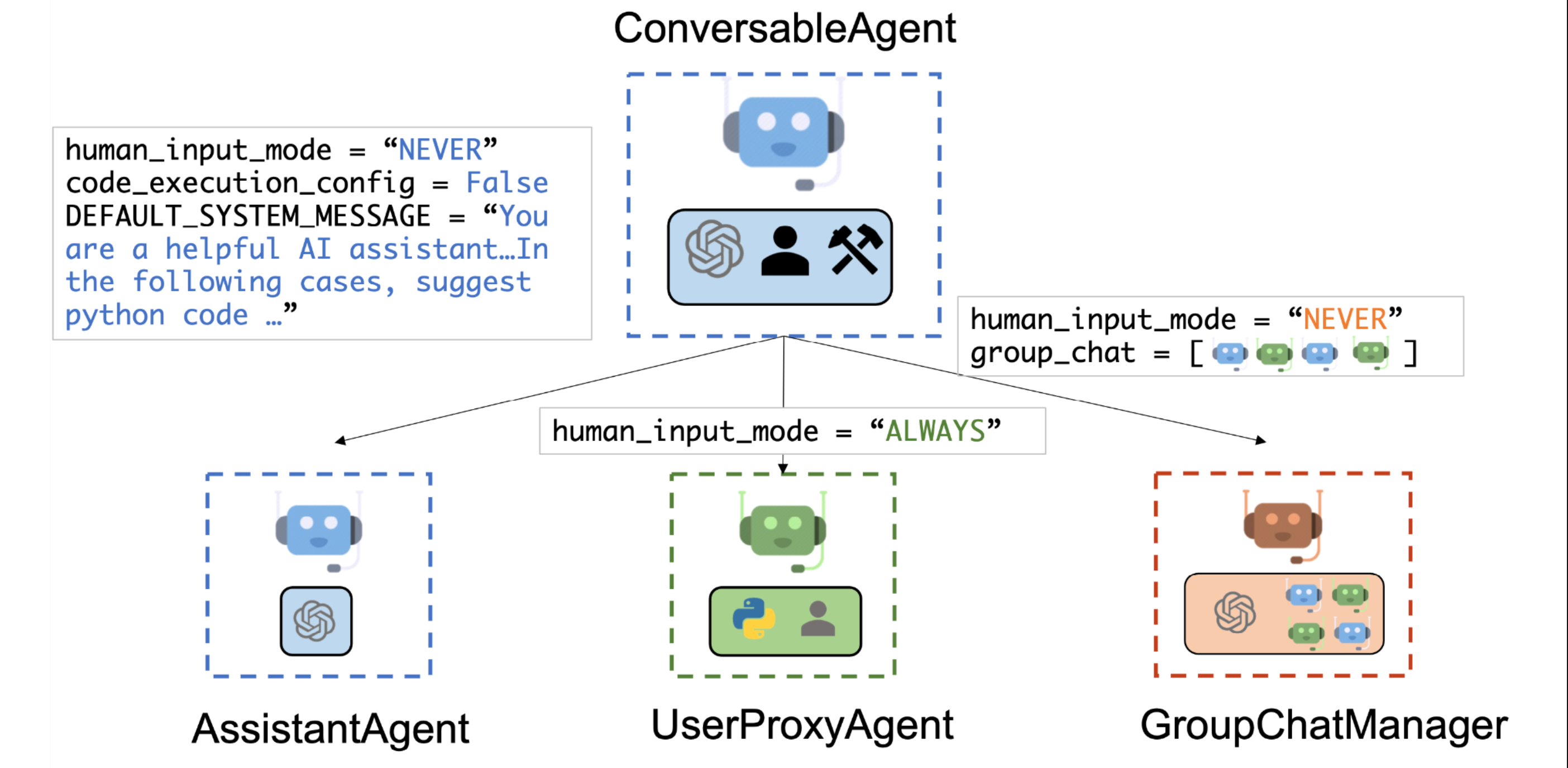
UserProxyAgent用户
user_proxy = UserProxyAgent配置说明:
# 构造参数
def __init__(
self,
name: str,
is_termination_msg: Optional[Callable[[Dict], bool]] = None,
max_consecutive_auto_reply: Optional[int] = None,
human_input_mode: Literal["ALWAYS", "TERMINATE", "NEVER"] = "ALWAYS",
function_map: Optional[Dict[str, Callable]] = None,
code_execution_config: Union[Dict, Literal[False]] = {},
default_auto_reply: Optional[Union[str, Dict, None]] = "",
llm_config: Optional[Union[Dict, Literal[False]]] = False,
# 默认不使用LLM,如果使用了LLM将会推测人的行为
system_message: Optional[Union[str, List]] = "",
description: Optional[str] = None,
)
重要参数说明:
human_input_mode
三种形式的说明:
三种模式都会涉及代码执行,需要代码执行根据实际要求来进行
| 模式 | 说明 (userproxy执行代码过程在code_execution_config配置中,后附说明) |
|---|---|
| ALWAYS | 每次接收到消息时,代理都会提示人类输入。当人类输入为 “exit”,或者 is_termination_msg 为 True 并且没有人类输入时,会话将停止。userproxy不会执行代码,代码执行交给使用用户,一轮对话都需要人为输入去干涉,Assistantproxy才能进行下去。不推荐:(如果回复中涉及代码)需要用户去执行代码并配置相关环境 |
| TERMINATE | 只有在接收到终止消息或者连续自动回复的数量达到 max_consecutive_auto_reply 时,代理才会提示人类输入。 userproxy会根据max_consecutive_auto_reply次数+Assistantproxy是否需要人为提供更多信息 来终止代码执行,结束标记为Assistantproxy to userproxy的最后一轮对话包含TERMINATE这个单词(可能大小写混合也可能夹杂其他单词,但一定有该单词.upper()存在)推荐:(如果回复中涉及代码)代码执行+需要人为提供更多的信息以保证更加准确的进行 |
| NEVER | 代理永远不会提示人类输入。在这种模式下,当连续自动回复的数量达到 max_consecutive_auto_reply 或者 is_termination_msg 为 True 时,会话将停止。userproxy会一直执行代码,配合参数default_auto_reply+max_consecutive_auto_reply直到停止较推荐:若涉及代码会进入死胡同,例如提供一些接口API密钥等,人不会去提供,直到轮数结束返回信息。 |
当 max_consecutive_auto_reply为0 的时候并且输入模式为TERMINATE的时候,get_human_input会被重写,否则不会被重写。
is_termination_msg
参数:
is_termination_msg 是一个函数,它接受一个字典形式的消息作为输入,并返回一个布尔值,表示这个接收到的消息是否是一个终止消息,即一个userproxy是否终止对话的标记。包含如下键值对:
# 键值对
"content":消息的内容
"role":发送消息的角色
"name":发送消息的名称
"function_call":函数调用的信息
code_execution_config
是一个字典或者布尔值,用于配置代码执行的相关设置。如果你想禁用代码执行,可以将其设置为 False。否则,你可以提供一个字典,其中包含以下键:
work_dir(可选,字符串):用于代码执行的工作目录。如果没有提供,将使用默认的工作目录。默认的工作目录是 "path_to_autogen" 下的 "extensions" 目录。
use_docker(可选,列表、字符串或布尔值):用于代码执行的 Docker 镜像。默认值为 True,这意味着代码将在 Docker 容器中执行,并将使用默认的镜像列表。如果提供了一个镜像名称的列表或字符串,代码将在成功拉取的第一个镜像的 Docker 容器中执行。如果为 False,代码将在当前环境中执行。我们强烈建议使用 Docker 来执行代码。
timeout(可选,整数):代码执行的最大时间(以秒为单位)。
last_n_messages(实验性的,可选,整数):用于代码执行的回溯消息数量。默认值为 1。
llm_config
这决定了 ConversableAgent 中反馈是通过 OpenAIWrapper 进行处理还是不进行任何 LLM 基础的回复处理。
默认值为 False,这将禁用基于 llm 的自动回复。
如果设置为 None,将使用 self.DEFAULT_CONFIG,其默认值也是 False。
简单来说,这个参数用于控制是否使用语言模型进行自动回复,以及如何配置这个语言模型。
如果需要配置LLM 参考文档 (配置同AssistantAgentde llm_config) 或同下
https://microsoft.github.io/autogen/docs/reference/oai/client/#create
AssistantAgent代理
构造参数:
def __init__(
self,
name: str, # 本项目使用请求的uuid来进行对话
system_message: Optional[str] = DEFAULT_SYSTEM_MESSAGE,
llm_config: Optional[Union[Dict, Literal[False]]] = None,
is_termination_msg: Optional[Callable[[Dict], bool]] = None,
max_consecutive_auto_reply: Optional[int] = None,
human_input_mode: Optional[str] = "NEVER",
description: Optional[str] = None,
**kwargs,
):
llm_config
样式构造:
llm_config={
"config_list": [{
"model": config.LLM_CONFIG[llm_provider]["MODEL"],
"api_key": config.LLM_CONFIG[llm_provider]["OPENAI_API_KEY"],
# "base_url": config.LLM_CONFIG[llm_provider]["OPENAI_API_BASE"],
"azure_endpoint": config.LLM_CONFIG[llm_provider]["OPENAI_API_BASE"],
"api_type": "azure",
"api_version": config.LLM_CONFIG[llm_provider]["API_VERSION"],
"model_client_cls": "OpenAIClientWithStream",
"cache_seed": None,
}],
"temperature": assistant_config["temperature"],
"timeout": 600,
"cache_seed": None,
"stream": True,
}
max_consecutive_auto_reply
默认值为 None,这意味着没有提供限制,此时将使用类属性 MAX_CONSECUTIVE_AUTO_REPLY 作为限制。
这个限制只在 human_input_mode 不为 "ALWAYS" 时起作用。
简单来说,这个参数用于控制一个 AI 助手在没有人类输入的情况下,可以连续自动回复的次数。
如果超过这个限制,AI 助手可能会停止自动回复,直到收到新的人类输入。
GroupChat群聊
类的构造参数:
agents: List[Agent] #对话者列表:一般就是一个用户多个代理:agents=[user_proxy, *assistants]
messages: List[Dict]
max_round: Optional[int] = 10
admin_name: Optional[str] = "Admin"
func_call_filter: Optional[bool] = True
speaker_selection_method: Union[Literal["auto", "manual", "random", "round_robin"], Callable] = "auto"
allow_repeat_speaker: Optional[Union[bool, List[Agent]]] = None
allowed_or_disallowed_speaker_transitions: Optional[Dict] = None
speaker_transitions_type: Literal["allowed", "disallowed", None] = None
enable_clear_history: Optional[bool] = False
send_introductions: bool = False # 可配置history 内容
messages
messages属性是一个列表,用于存储群聊中的所有消息。每个消息都是一个字典,包含了消息的相关信息。 当一个新的消息被添加到群聊中时,它会被添加到messages列表的末尾。这个列表可以用来跟踪群聊的历史记录,包括每个参与者发送的所有消息。 例如,当一个代理(Agent)在群聊中发言时,它的发言会被添加到messages列表中。这样,其他的代理就可以查看这个列表,了解群聊的历史记录,以便做出相应的回应。
speaker_selection_method
def custom_speaker_selection_func(
last_speaker: Agent,
groupchat: GroupChat
) -> Union[Agent, Literal['auto', 'manual', 'random' 'round_robin'], None]:
决定了在群聊中如何选择下一个发言者
1.”auto”:下一个发言者由LLM(语言模型)自动选择。
2.”manual”:下一个发言者由用户手动输入选择。
3.”random”:下一个发言者随机选择。
4.”round_robin”:下一个发言者按照 agents 列表中的顺序轮流选择。
5.自定义的发言者选择函数(Callable):这个函数会被调用来选择下一个发言者。这个函数应该接受上一个发言者和群聊作为输入,并返回以下三种可能的值之一:
一个 Agent 类,它必须是群聊中的一个代理。
一个字符串,从 [‘auto’, ‘manual’, ‘random’, ‘round_robin’] 中选择一个默认的方法来使用。
None,这将优雅地终止对话。
GroupChatManager管理者
构造参数:
def __init__(
self,
groupchat: GroupChat,
name: Optional[str] = "chat_manager",
# unlimited consecutive auto reply by default
max_consecutive_auto_reply: Optional[int] = sys.maxsize,
human_input_mode: Optional[str] = "NEVER",
system_message: Optional[Union[str, List]] = "Group chat manager.",
**kwargs,
):
【OLD】发送历史信息【请使用resuming新特性】
使用GroupChat,需要在user_proxy.initiate_chat之前发送历史消息:
manager.send(msg["content"], recipient=assistant, request_reply=False, silent=False)
区别于不用GroupChat的时候,只有一个userproxy和assistantproxy的时候发送历史信息如下:
userproxy.send(msg["content"], recipient=assistant, request_reply=False, silent=False)
为什么GroupChat是这个流程?因为这样提前发送的信息是manager作为发送方,assistant作为接收方,满足GroupChat的轮对话的过程,但请注意需要把content作为陈述句发送给assistant,否则新一次回答后会再次回复历史信息的问题。
Resuming GroupChat (新特性)
本特性目前只在github开源版本有【0531 pip包已更新】,需要自己下载或者更新最新版本导包(pyautogen版本0.28)
本特性功能就是高效、快速加载历史记录信息,之前是利用如上OLD标题的方式进行加载历史。
resume function (or a_resume for asynchronous workflows).
注意:官方说明resmume :returns the last agent in the messages as well as the last message itself(返回最后一个代理体的最后一条消息)
传入参数说明: JSON 字符串或消息的列表(List[Dict]) 【样式可来源于上一次对话的 ChatResult 的 chat_history 或 GroupChat 的 messages 属性】
样式JSON格式:
[{"content": "Find the latest paper about gpt-4 on arxiv and find its potential applications in software.", "role": "user", "name": "Admin"}, {"content": "Plan:\n1. **Engineer**: Search for the latest paper on GPT-4 on arXiv.\n2. **Scientist**: Read the paper and summarize the key findings and potential applications of GPT-4.\n3. **Engineer**: Identify potential software applications where GPT-4 can be utilized based on the scientist's summary.\n4. **Scientist**: Provide insights on the feasibility and impact of implementing GPT-4 in the identified software applications.\n5. **Engineer**: Develop a prototype or proof of concept to demonstrate how GPT-4 can be integrated into the selected software application.\n6. **Scientist**: Evaluate the prototype, provide feedback, and suggest any improvements or modifications.\n7. **Engineer**: Make necessary revisions based on the scientist's feedback and finalize the integration of GPT-4 into the software application.\n8. **Admin**: Review the final software application with GPT-4 integration and approve for further development or implementation.\n\nFeedback from admin and critic is needed for further refinement of the plan.", "role": "user", "name": "Planner"}, {"content": "Agree", "role": "user", "name": "Admin"}, {"content": "Great! Let's proceed with the plan outlined earlier. I will start by searching for the latest paper on GPT-4 on arXiv. Once I find the paper, the scientist will summarize the key findings and potential applications of GPT-4. We will then proceed with the rest of the steps as outlined. I will keep you updated on our progress.", "role": "user", "name": "Planner"}]
抽象化:
[{"content": "XXXXX","role":"user","name":"userproxy"},{},{}]
测试实例代码:
#样例代码:
from typing import Union, Dict
from autogen import AssistantAgent, UserProxyAgent, GroupChatManager, GroupChat, ConversableAgent
import os
import time
import warnings
warnings.filterwarnings("ignore", category=RuntimeWarning)
start_time = time.time() # 获取当前时间
# gpt-3.5-turbo syner-openai-gpt40-eastus
llm_config = {"model": "gpt-3.5-turbo", "api_key": "sk-v,","base_url":"https://a"}
assistant = AssistantAgent("a", llm_config=llm_config)
assistant2 = AssistantAgent("b", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config={"work_dir": os.getcwd(),"use_docker": False} ,human_input_mode="NEVER",max_consecutive_auto_reply=2)
groupchat = GroupChat(
agents=[user_proxy,assistant,assistant2],
messages=[],
)
manager = GroupChatManager(groupchat=groupchat,llm_config=llm_config)
message1 = [{"content":"北京是怎么样","role":"user","name":"user_proxy"},{"content":"北京是一个不错的城市","role":"assistant","name":"a"},{"content":"这个城市环境怎么样","role":"user","name":"user_proxy"}]
# 在messages1列表最后一个JSON中,就是你需要提问的角色和问题,而前面的JSON就是你需要传入的history信息
last_agent, last_message = manager.resume(messages=message1)
# 将最后的角色和信息得到,然后由它发起对话,见下代码,这样就保存信息了
result = last_agent.initiate_chat(recipient=manager,message=last_message,clear_history=False)
print(result)
end_time = time.time() # 获取当前时间
print(f"执行时间: {end_time - start_time} 秒")
关键的操作就是: 把之前保存的信息(或需要传到下一轮对话的信息)放进一个list,按照如下格式:
pre_mess = [{"content": "XXXXX","role":"user","name":"userproxy"},{},{}]
上面pre_mess 就是一个之前的保存信息list,然后通过前端新传入的message添加到上面list的末尾:
pre_mess.append(message);
last_agent, last_message = manager.resume(messages=pre_mess)
#得到历史消息,并获取pre_mess最后的一个信息和代理体
#开启对话
result = last_agent.initiate_chat(recipient=manager,message=last_message,clear_history=False)
llm_config
在manager的配置中:关于llm参数的说明如下,作为**kwargs参数传递:
if (
kwargs.get("llm_config")
#通过 kwargs.get() 方法尝试获取关键字参数 llm_config 的值。
#如果该参数存在,则返回其对应的值,否则返回 None
and isinstance(kwargs["llm_config"], dict)
# 使用 isinstance() 函数检查 llm_config 参数的值是否为字典类型。
#如果是字典类型,则返回 True,否则返回 False。
and (kwargs["llm_config"].get("functions") or kwargs["llm_config"].get("tools"))
# 通过 get() 方法尝试获取 llm_config 参数字典中的 "functions" 或 "tools" 键对应的值。
#如果其中一个键存在且对应的值为真值(即不是 None、空字符串、空列表等),则整个表达式的值为真值,否则为假值。
):
raise ValueError(
"GroupChatManager is not allowed to make function/tool calls. Please remove the 'functions' or 'tools' config in 'llm_config' you passed in."
)
意思是说:如果要构造此参数需要llm_config 参数存在且是字典类型,且其中至少有一个键 “functions” 或 “tools” 对应的值为真值
官方人的解释:
The manager needs llm config if you use auto speaker selection.
The round robin speaker selection method doesn’t need it.
没有包含 "functions" 或 "tools"。
因此,按照你的代码逻辑,这不会触发构造函数中的异常抛出,你的 llm_config 是可以接受的。
llm_config参数配置(全)
在userproxy、assistant、manager之中,都继承ConversableAgent,都含有llm_config参数:
官方列出了三种在config_list的键值对情况:
OpenAI (以及其他类OpenAI的接口)
model(str, required): The identifier of the model to be used, such as ‘gpt-4’, ‘gpt-3.5-turbo’.api_key(str, optional): The API key required for authenticating requests to the model’s API endpoint.base_url(str, optional): The base URL of the API endpoint. This is the root address where API calls are directed.tags(List[str], optional): Tags which can be used for filtering.
Azure OpenAI:
model(str, required): The deployment to be used. The model corresponds to the deployment name on Azure OpenAI.api_key(str, optional): The API key required for authenticating requests to the model’s API endpoint.api_type:azurebase_url(str, optional): The base URL of the API endpoint. This is the root address where API calls are directed.api_version(str, optional): The version of the Azure API you wish to use.tags(List[str], optional): Tags which can be used for filtering. (主要用于选择model)
config_list = [
{
"model": "gpt-4",
"api_key": os.environ['OPENAI_API_KEY']
}
]
# If one model times out or fails, the agent can try another model
# 这是一个列表,在这里可以添加多个model,一个失败了,就使用另一个进行
# e.g. use cheaper GPT 3.5 for agents solving easier tasks
# 按照配置的顺序去请求各个模型
如果列表中有多个模型,需要指定models的话:
filter_dict = {"model": "gpt-3.5-turbo"}
config_list = autogen.filter_config(config_list, filter_dict)
#或
filter_dict = {"tags": ["llama", "another_tag"]}
config_list = autogen.filter_config(config_list, filter_dict)
其他模型client参数
a_initiate_chat初始对话
同步和异步均类似,这里以异步async为主,不加a_的方法为同步。
函数使用对象为user_proxy
该方法在ConversableAgent类中,而user_proxy 继承了ConversableAgent,但并没有重写方法。
函数传入参数:
async def a_initiate_chat(
self,
recipient: "ConversableAgent",
clear_history: bool = True,
silent: Optional[bool] = False, # 如果是False,则会在控制台输出每轮对话的过程
cache: Optional[Cache] = None,
max_turns: Optional[int] = None,
summary_method: Optional[Union[str, Callable]] = DEFAULT_SUMMARY_METHOD,
#summary_method:这是一个可选的字符串或可调用对象,用于从聊天中获取摘要。
#默认是 DEFAULT_SUMMARY_METHOD,即 "last_msg"。
summary_args: Optional[dict] = {},
message: Optional[Union[str, Callable]] = None,
**context,
) -> ChatResult:
返回参数说明:
chat_result = ChatResult(
chat_history=self.chat_messages[recipient],
summary=summary,
cost=gather_usage_summary([self, recipient]),
human_input=self._human_input,
)
样式chat_history:
[{'content': '', 'role': 'assistant'},
{'content': '北京的天气如何', 'role': 'assistant'},
{'content': '我将使用Python来获取北京的天气信息。请稍等片刻。', 'role': 'user'},
{'content': 'go on', 'role': 'assistant'},
{'content': '抱歉,我无法直接获取北京的天气信息。您可以使用天气预报网站或者天气预报应用程序来获取北京的天气信息。', 'role': 'user'},
{'content': 'go on', 'role': 'assistant'}]
summary_method
返回的形式:str 或 callable
Str样式:
Supported strings are “last_msg” and “reflection_with_llm”(由llm来进行摘要处理)
样例对话:
await user_proxy.a_initiate_chat(
message=message,
#silent=True,
silent=False,
recipient=assistants[0], # 聊天的接受者
clear_history=False,
)
a_get_human_input
在ConversableAgent(LLMAgent)类下面
重写该方法自定义在ALWAYS TERMINATE模式下的用户输入
函数实现方法:
async def a_get_human_input(self, prompt: str) -> str:
reply = input(prompt)
self._human_input.append(reply)
return reply
函数的主要部分是 input(prompt),这是 Python 的内置函数,用于从命令行读取用户的输入。当 input() 函数被调用时,程序运行会暂停,等待用户输入。用户输入的内容将作为字符串返回,并被赋值给 reply 变量。
run_code
ConversableAgent(LLMAgent)类
def run_code(self, code, **kwargs):
return execute_code(code, **kwargs)
文本压缩(新特性)
官方主要提供两种解决方法:1.直接调用 LLMLingua进行压缩(免费) 2.将压缩的技能添加到assistant中,然后开启对话(个人对文本token对了方法判断)
import fitz # PyMuPDF
import os
import autogen
from autogen.agentchat.contrib.capabilities.text_compressors import LLMLingua
from autogen.agentchat.contrib.capabilities.transforms import TextMessageCompressor
from autogen.agentchat.contrib.capabilities import transform_messages
# 为了避免死锁,tokenizers库禁用了并行处理。通过如下来禁用这个警告:
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# 提取PDF的文本内容
def extract_text_from_pdf(file_path):
text = ""
with fitz.open(file_path) as doc:
for page in doc:
text += page.get_text()
return text
# 指定本地PDF文件的路径
local_pdf_file_path = "test.pdf"
# 提取PDF文本
pdf_text = extract_text_from_pdf(local_pdf_file_path)
# 初始化文本压缩器
llm_lingua = LLMLingua()
text_compressor = TextMessageCompressor(text_compressor=llm_lingua, compression_params={"target_token": 5000})
# 应用文本压缩
compressed_text = text_compressor.apply_transform([{"content": pdf_text}])
compressed_text_str = compressed_text[0]["content"]
# 打印压缩后的文本
print(compressed_text)
# 定义对话系统的配置
system_message = "你是一个总结大师。"
config_list = [{"model": "gpt-3.5-turbo", "api_key": "sk-SJz4O2cXquzxkGB162C3Ae941d454c1fBa5dA0A74eEbAa6a","base_url":"https://oneapi.zhiji.ai/v1"}]
researcher = autogen.ConversableAgent(
"assistant",
llm_config={"config_list": config_list},
max_consecutive_auto_reply=1,
system_message=system_message,
human_input_mode="NEVER",
)
user_proxy = autogen.UserProxyAgent(
"user_proxy",
human_input_mode="NEVER",
is_termination_msg=lambda x: "TERMINATE" in x.get("content", ""),
max_consecutive_auto_reply=1,
code_execution_config={"work_dir": os.getcwd(), "use_docker": False}
)
context_handling = transform_messages.TransformMessages(transforms=[text_compressor])
context_handling.add_to_agent(researcher)
# 针对于对话模式,下面个人提供了两种解决办法用来处理输入输出消耗过大token的情况
# 法一:判断pdf_text的token数,如果超过5000,那么直接使用免费模型压缩后的文本进行对话,否则作为messgae进行传递并且结合
# 判断原始文本的长度,并选择合适的文本进行对话
token_limit = 5000
original_token_count = len(pdf_text) # 简单使用字符数作为token数的估计
if original_token_count > token_limit:
message = "总结这段信息:" + compressed_text_str
else:
message = "总结这段信息:" + pdf_text
# 初始化对话
result = user_proxy.initiate_chat(recipient=researcher, clear_history=True, message=message, silent=True)
# 打印对话结果
print(result.chat_history[1]["content"])
# 法二:将pdf_text分割成多个长度不超过6000的子序列,然后分段进行输出总结。不过运行时间长,需要从头到尾进行对话
# def chunked_input(sequence, max_length):
# return [sequence[i:i + max_length] for i in range(0, len(sequence), max_length)]
#
# # 在你的代码中,将长序列分割成多个长度不超过6000的子序列
# chunked_sequences = chunked_input(pdf_text, 6000)
#
# # 然后,你可以将这些子序列分别输入到模型中
# for sequence in chunked_sequences:
# message = "总结这段信息" + sequence
# result = user_proxy.initiate_chat(recipient=researcher, clear_history=True, message=message, silent=True)
# print(result.chat_history[1]["content"])
execute_code
Docker :默认运行环境,是完整镜像的配对版本,它与默认镜像拥有一样的系统和包管理工具,但省略许多不常用的依赖,故而它变得很小。但这意味着需要一些不常用的依赖时,需要自己安装。需要有sh python解释器。(atexit为退出镜像)
DockerCommandLineCodeExecutor
如果:
ode_execution_config={"work_dir": os.getcwd(),"use_docker": True}
默认docker每次执行完会重新建一个环境,pip 安装的包会没有,如果想用docker可以设置镜像名称,使得pip包可以不再重复安装
Local (本地)
user_proxy = autogen.UserProxyAgent(
name="agent", llm_config=llm_config,
code_execution_config={"work_dir":"coding", "use_docker":False})
轮数参数对比
max_consecutive_auto_reply vs max_turn vs max_round
max_consecutive_auto_reply :(在Agent代理类)最大连续自动回复次数(代理人的回复没有人类输入被视为自动回复)当human_input_mode不是“ALWAYS”时起作用。
max_turn (ConversableAgent.initiate_chat方法中)限制了两个可对话的代理之间的对话轮数(不区分自动回复和人类回复/输入)这里的一个turn表示两个代理之间的对话,即一个turn对应对话的两次
max_round (GroupChat) : 指定群聊会话中的最大轮数。默认为None,那么对话会在terminate结束
获取每轮对话与全部对话
re = user_proxy.initiate_chat(
silent=False,
# recipient=manager,
recipient=assistant,
message="北京的天气如何",
)
print(user_proxy.chat_messages_for_summary(assistant))
输出形式如下:
[{'content': '北京的天气如何', 'role': 'assistant'}] 会有多轮对话的显示
print(user_proxy.last_message(assistant)) # 只输出最后一次assistant的内容,格式同上
回复终止对话
AutoGen自动知道停止向LLM发送更多的信息,写在系统提示词:When you are satisfied that the task is complete, reply with ‘TERMINATE’.。当LLM返回TERMINATE代表结束。
链接:https://www.reddit.com/r/AutoGenAI/comments/18nrx66/termination_message_explanation/
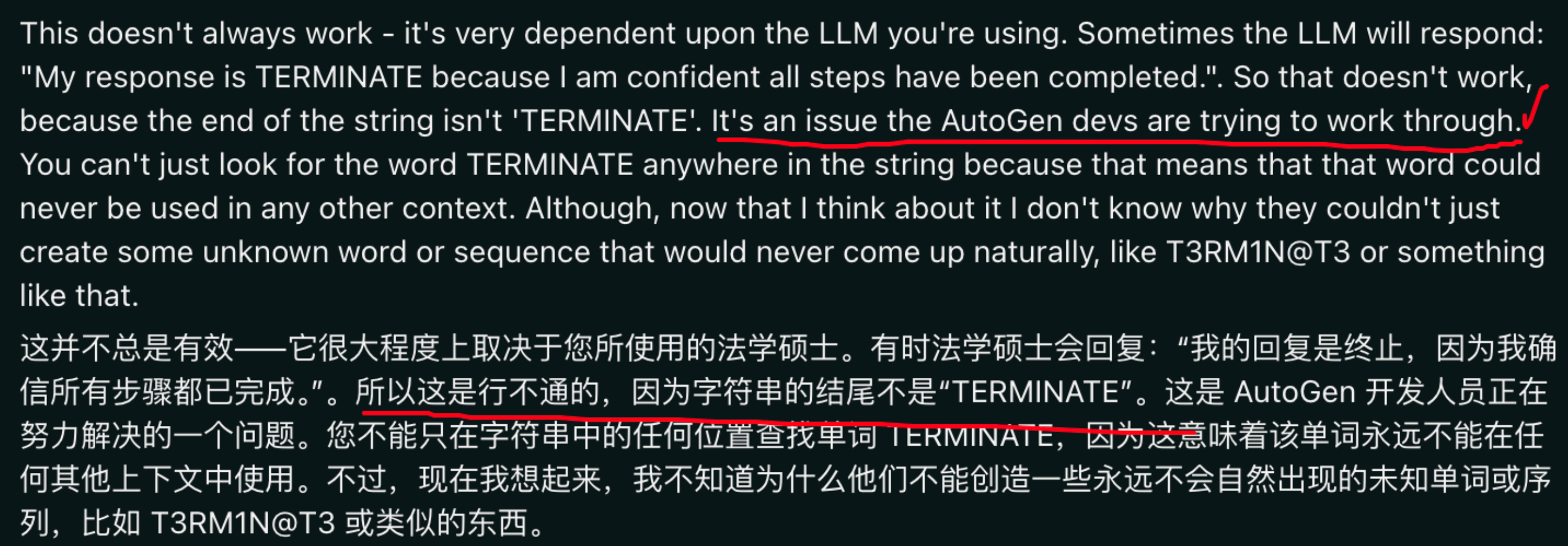
终止对话的AutoGen配置触发器 (Agent类里面):
max_consecutive_auto_reply:
is_termination_msg:自定义函数,例如包含单词就终止

Github中重要issue
1、GroupChat history message 【已解决,利用resuming groupchat新特性】之前先send信息作为记录保存
https://github.com/microsoft/autogen/issues/229
测试代码,以Autogen 同步框架为例:
from autogen import AssistantAgent, UserProxyAgent
import os
import warnings
warnings.filterwarnings("ignore", category=RuntimeWarning)
llm_config = {"model": "gemini-pro", "api_key": "sk-V","base_url":"http://127.0.0.1:300/v1"}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config={"work_dir": os.getcwd(),"use_docker": False} ,human_input_mode="TERMINATE",max_consecutive_auto_reply=4)
re = user_proxy.initiate_chat(
assistant,
silent=False,
message="北京的天气如何,如果使用代码,请使用python代码进行书写,不要使用shell代码,直接告诉我具体的数值就可以不用图表,同时assistant (to user_proxy)回复的话必须全都是中文,除非是代码",
)
print("********************")



